

































Private Cloud as a service. Bare Metal as a service.
Modern cloud. Transparent costs. No overruns.
![]()
OpenMetal Starter Cloud
Launch your own hosted private cloud on a 3 server Cloud Core – all in 45 seconds.
![]()
On-Demand OpenStack
The #1 cloud management system you love, delivered right now, root and all.
Dedicated Bare Metal
Support demanding workloads such as ClickHouse, Kafka, Hadoop, Spark, Cassandra, and more.
Ceph Storage Clusters
Large scale storage clusters for bulk object storage plus Block and Network File System.
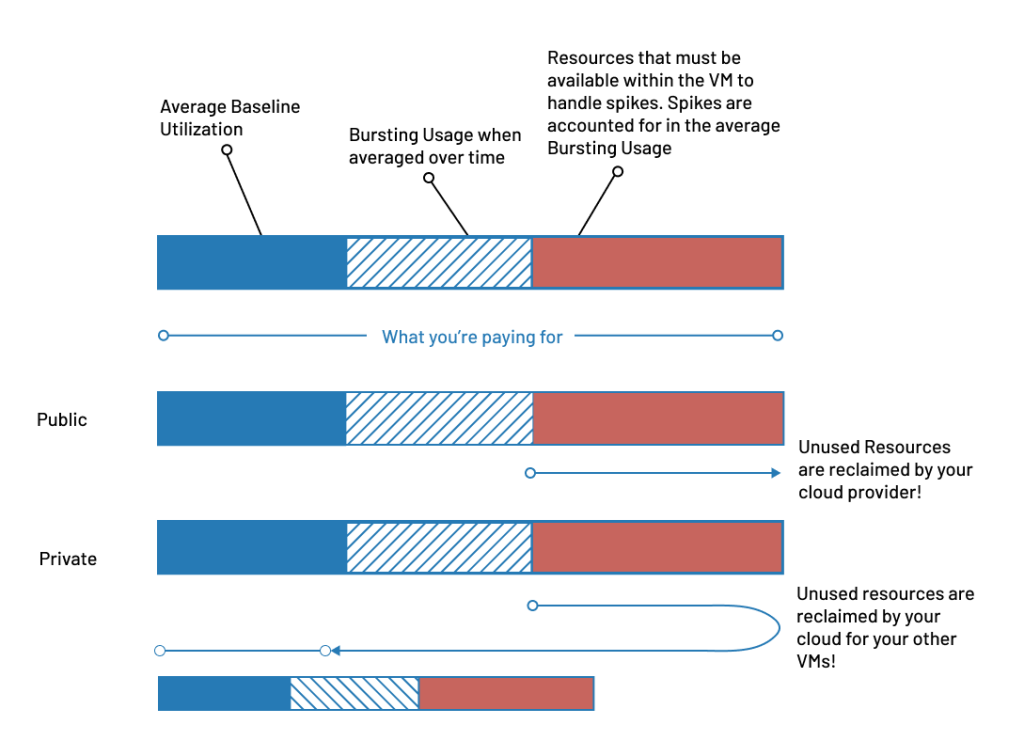
VM Resource Management – Public vs Private Cloud
![]() Average Used
Average Used ![]() Average Burst
Average Burst ![]() Wasted
Wasted
Read more about this fundamental advantage.
High Performance. Fair Costs.
Bring 50%+ cloud cost savings back to you.
Costs are out of control on traditional public clouds. One of the key benefits of a private cloud is its cost advantage at scale. With OpenMetal, your cloud benefits from the fundamental advantage of private clouds – you are leasing all the resources of the hardware and not just the virtual resources.
When you provision a VM you can provision the size you need, but during the time that VM is not spiking to consume the top level limit of the VM, those previously wasted resources are dynamically returned to you for your other VMs! You can both raise performance and lower costs by as much as 50%.
Commitment to Community & Collaboration
Our journey is shaped by a commitment to excellence and the spirit of community. By joining hands with leading industry foundations, OpenMetal is not just a participant but an active contributor to the open source ecosystem, ensuring that we provide cutting-edge cloud solutions while nurturing a culture of shared knowledge and progress.




Working Together for Your Success
Your team is the kind of people we would dream of having on our own team. And the great thing about working with you is that it feels like they are part of our team. This quickly won over trust with us.
What is OpenMetal?
OpenMetal is a leading provider of open source private cloud as a service and dedicated servers as a service. The strengths of public cloud, private cloud, and bare metal have been fused into an alternative cloud platform, powered by OpenStack, Ceph, and bare metal automation.
Advantages Over Traditional Public Cloud
- Up to 3.5x more efficient than public cloud
- Set your hardware budget, no surprise bills
- Fair egress costs
Advantages Over Traditional Private Cloud
- Instant provisioning, scale up and down easily
- No hardware management
- No license costs
| Private | Public | |
|---|---|---|---|
| Tenant-First Goals | |||
| Private Security Model | |||
| Root Control | |||
| Dedicated to You | |||
| Tune to Workloads | |||
| Custom Flavors | |||
| Fair Egress Costs | |||
| No Surprise Billing | |||
| 4-5 Year Agreements | |||
| 1-3 Year Agreements | |||
| Pay as You Go | |||
| Launch Instantly | |||
| Self Service Purchasing | |||
| Rapid Scaling | |||
| Managed Hardware | |||
| Rapid PoCs | |||
| Easy Multi-Region |
Explore cloud features, check cloud core pricing, or come meet us!

S&P Global Coverage of OpenMetal
William Fellows, Research Director at S&P Global Market Intelligence firm positions OpenMetal’s On-Demand OpenStack Private Cloud as a cheaper, more efficient alternative to hyper scalers.
OpenMetal Industry Programs
Special support, pricing, and hardware to match your business model.
Hosting and Cloud Providers
Empower your unique offerings and lower all-in costs.
Education and Training
Build from a Day 2 ready cloud configuration and deployment.
Media and Press
- MyMiniFactory’s Journey to Cloud Infrastructure Scalability and Reliability: Powered by OpenMetal
- WordPress PaaS Provider, Convesio, Achieves Significant Cloud Advantages Moving to OpenMetal
- OpenMetal Officially Launches On-Demand OpenStack Cloud Service Operations in Europe with Amsterdam Data Center
Best-In-Class Cloud Technology
The tech you love, the options you want, the API-first approach you need.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All from people that believe in the power of open source
Open Source at the Core
Discover the driving motivation behind the development of OpenMetal and its commitment to support the growth and advancement of open source and its communities.
Innovation On Demand
Learn how to harness the power of OpenMetal to build and deploy enterprise-level, OpenStack private clouds for companies of any size, in less than a minute.
“It’s really awesome to work with someone who’s aligned culturally to the same type of mission that we are. And it’s really provided us with the ability to innovate and differentiate from the masses that are out there all using the same hyperscalers.”
Tom Fanelli, CEO and Co-Founder of Convesio
“A huge benefit for us both in cost savings and, of course, functionality.”

Gary MacDougall, CTO
Pypestream

“OpenMetal Cloud provides on-demand private infrastructure, which brings cloud fundamentals like elasticity and usage billing to the cloud deployment itself. It’s awesome to see OpenMetal’s latest product use OpenStack to combine the benefits of public cloud and managed private cloud, powered by open infrastructure.”

Thierry Carrez, VP of Engineering
Open Infrastructure Foundation
Powered by Open Source
OpenMetal is a Silver Member of the OpenInfra Foundation. The OpenMetal Cloud Core is powered by OpenStack, the #1 open source cloud infrastructure platform; plus Ceph, the #1 open source storage system in the world. OpenStack Private Clouds, hosted private clouds, managed private clouds, and storage clusters are all proudly run on open source. You can be confident you’re getting the right cloud IaaS solution with the support of a leading OpenStack provider.

