

































Erasure Coding
Erasure coding can be a bit confusing. It is also typically a decision that involves trade-offs between I/O performance needed for a particular storage process, initial and ongoing cost of the setup, and usable storage.
We have experience creating clusters using Erasure Coding for our internal use and for production mass backup systems. We also use Ceph clusters as our storage for our new IaaS OpenMetal Clouds. These use On-Demand OpenStack private clouds to help scale up and down as needed. They can range from a 3 server hyper-converged OpenStack and Ceph using replication to stand alone 20+ node Ceph clusters for object storage using erasure coding.
Erasure coding, boiled down, is just saying if you have a certain number of servers, you can decide how many of those servers will get the primary parts of your data (K) and how many of those servers will get the redundant parts of your data (M).
M is called the “Parity” data but can just be thought of as redundant data that can be lost itself or can be used to replace a primary set of data (K) in case it is lost. What really matters is how much disk space you can use and how many copies can be lost before you lose data.
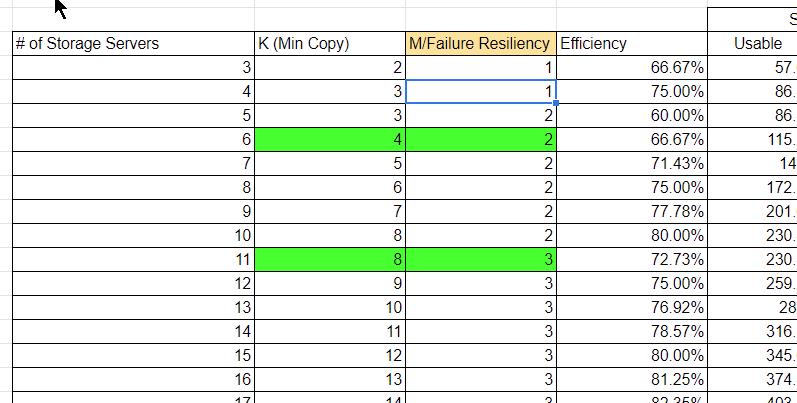
Disk Space Available for Use = # of OSD * (K/(K+M)) * OSD Size * Recommended Usage Max
Erasure Coding Calculator
To help ensure great pricing for our customers, we looked at Erasure Coding for the larger clusters, including specifically the efficiency and data protection of different K and M values. We used this to create our overall OpenStack Pricing Calculator for our OpenMetal Cloud. Also, we have a cool JavaScript App coming soon!
After doing this work and having to look up quite a bit about Erase Coding, we have created the below spreadsheet that might be useful for you. It can help you price out storage costs while also understanding how Erasure Coding works.
It is missing a few things, but if you find this useful, please connect with me on LinkedIn or leave a comment below with what could be added. Missing things:
- Does not take into account compression. For our large Ceph clusters the hardware combination has enough CPU and NVMe accelerators so it can support quite a bit of “on the fly” compression. It means if you have 100TB to store, it might end up as only 80TB on disk after compression.
- Hardware costs are “made up” based on what is out there, not specific manufactures, you need to add your numbers for your costs.
- This does not take into account time and energy of acquiring the hardware, configuring the setup, etc. That is usually added in, then amortized for startup, and a monthly cost for running the cluster. This is obviously very significant but there may be time available from the systems team and the network team so it isn’t an extra cost. Add to the sheet for your situation.
- This Erasure Coding calculator does not speak to planning for your cluster to “self heal”. What we mean by self healing Ceph is to setup Ceph to decide what to do when in a Degraded State. Ceph will be aware when hardware has failed. This can be at the single drive level, an OSD, or at the server level, or even at the rack level. If Ceph has been setup with 11 boxes and K=8 and M=3 but a server fails that has one of those records. For ease, lets pretend it is just one of the M records. Ceph will know that its current state is now K=8 and M=2 but it is supposed to be K=8 and M=3. Ceph will want to re-create the missing M records and you can set rules in Ceph to handle this. Essentially, if you have sufficient free space on the remaining 10 boxes, Ceph can then become a K=7 and M=3 cluster. The M is the critical part, it is the tolerance to failure metric. Ceph will self heal out of Degraded. When you have time you can address server 11 and then put it back into production without being fearful of catastrophic data loss.
Power Consumption and Erasure Coding
Power gets a special call out here. Included in the Calculator is a cost for “DC Ops Cost/Month w Power”. Power is a significant factor. These systems have lots of drives, a good amount of RAM, high throughput NIC cards, and typically dual CPUs. Erasure coding does a lot of calculations to create the K and M blocks. Don’t underestimate power by just including the U cost.
Calculator Spreadsheet
We do have our pricing calculator online now, but without further ado, here is the spreadsheet in different formats
- Google Drive Spreadsheet (should prompt you to make a copy)
- OpenOffice
- Excel
That’s it! Again, please connect with me on LinkedIn or leave a comment below with requests or questions — even corrections if I managed to mess up something! If this is a valuable article, you might also find our Automating OpenStack with Terraform interesting.
Also, if you believe in Open Source and your company is using a “Mega Public Cloud”, please consider our on demand OpenMetal Hosted Private Cloud. Built on Open Source, no lock in, better costs, and private from the start.