

































This article is written based on our background with our private clouds created with OpenStack and Ceph. Other cloud systems will have a bit of a different meaning regarding converged vs hyper-converged, but you will get the idea.
Some of the other sites attempting to explain this concept focus on something that might be the “older” description of Converged Infrastructure.
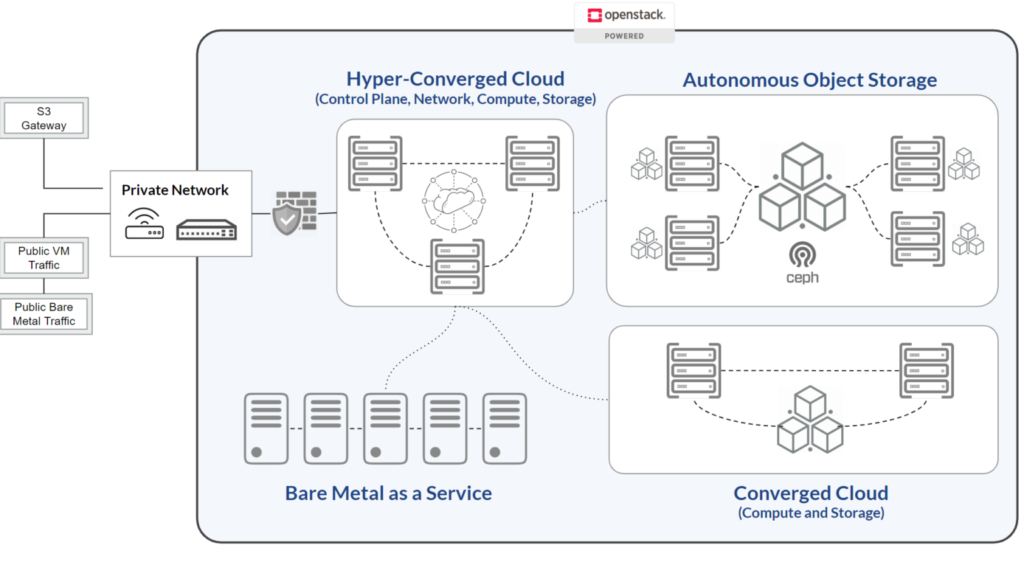
When someone asks me the difference between converged vs hyper-converged they are typically asking literally what are the different services running on the different servers in your cluster.
Hyper-Converged vs Converged in a OpenMetal Cloud
It is easier to start with what hyper-converged is, then converged, then stand alone, and then dis-aggregated (to throw another tech jargon word in there) to explain the differences. It also helps to introduce the following “dis-aggregated services”:
- Compute Nodes – these are servers specifically for Compute and would have
- Hypervisor or Containerization Tech – allows VMs or Containers to consume RAM and CPU on the hardware – in our OpenStack, KVM
- Ephemeral Storage – storage, if present, is not stateful or redundant off server – in our OpenStack, Ephemeral Storage
- Storage Nodes – these are servers with a bunch of SSDs or spinning hard drives and have
- Software that converts Hardware to stateful and redundant Network Storage – Ceph and the OSD concept
- Software that allows access to the Network Storage on this hardware in different ways – Ceph’s server-side part of RBD (servers up block devices), RGW (S3 Gateway), and CephFS (locking NFS like a file system)
- It could also be “boxes” that don’t have CPUs – dis-aggregated might mean it needs to be connected to a “compute” that is in a different chassis to function.
- Control Plane Nodes
- Software that controls the management of VMs, Containers, Storage, and Networking – OpenStack’s APIs and Horizon
- Software that allows access to the management system – OpenStack’s Keystone
- Network Nodes (or standalone appliances like your typical ToR Switch) – in the OpenStack world these are all handled on “general” servers via Linux services, not specific hardware devices. But specific accelerator cards are now making their way into “general” servers, so well, there is that.
- Routers
- Switches
- Firewalls
- Load Balancers
So, with that – Converged vs Hyper-Converged:
- Hyper-Converged = Compute, Storage, Control Plane, and Networking are all on one server
- Converged = Compute and Storage only are on server
Of note: “Dis-aggregated/Traditional” = All major Services are on autonomous hardware
It is also useful to explore how we recommend sizing your OpenMetal hyper-converged cluster due to the resource needs of the control plane.
Hyper-Converged Server
More explanation is possibly needed, so another way to look at it.
All of the stand-alone servers above represent Services that are a required part of modern infrastructure. But many of those Services do not require a lot of resources when part of a “small” deployment. To further complicate it, to have those Services be redundant like any good system admin will advocate for, you would need 2 or 3 of each. So now you would have several servers that do not require a lot of resources.
Hyper-Converged simply takes all 4 of those “service groups” and combines them onto a single hyper-converged server. With storage existing only on one server, you will, of course, not be “highly available” or have proper data protection. To solve this, in our private clouds, we use 3 hyper-converged servers and some people will now call it a hyper-converged cloud.
In this case, our 3 server Ceph cluster is replication mode for data protection. This is typically used for data that is primarily for block storage vs object storage. To have Ceph run as a large object storage system you would typically run it on stand-alone servers with things like Erasure Coding for storage efficiency.
Converged Server
In most Converged vs Hyper-Converged discussions, the term “Converged” will mean that Compute and Storage resources are on the same physical box. Let’s call this box “Converged 1”. In our hyper-converged infrastructure OpenStack world, this means the virtualization software – KVM – will be used to allow virtual machines to be created using the RAM and CPU resources on Converged 1.
In addition, one or more of the hard drives (in our case an NVME or SATA SSD) on Converged 1 will be part of another software system called Ceph. The “data storage” part of a Ceph cluster is resident on Converged 1 and will manage that specific SSD. As Ceph is horizontally scalable, there is also part of Ceph that will distribute data to other servers in the Ceph cluster – Converged 2, for example. Unlike the Hyper-Converged case, Ceph’s Monitoring, Object Storage Gateway, and some other Control Plane services do not run on Converged 1.
In Summary
Our marketing pages cover the specifics of converged vs hyper-converged cloud on our hosted private cloud page, please check it out if you are interested. If you are wondering why this is written from an OpenStack perspective – check out Why is OpenStack Important for Small Business.
OpenStack, But Easy
